Why Xarray-Beam¶
Our goals¶
Xarray-Beam is a Python library for building Apache Beam pipelines with Xarray datasets.
The project aims to facilitate data transformations and analysis on large-scale multi-dimensional labeled arrays, such as:
Ad-hoc computation on Xarray data, by dividing a
xarray.Datasetinto many smaller pieces (“chunks”).Adjusting array chunks, using the Rechunker algorithm.
Ingesting large, multi-dimensional array datasets into an analysis-ready, cloud-optimized format, namely Zarr (see also Pangeo Forge).
Calculating statistics (e.g., “climatology”) across distributed datasets with arbitrary groups.
Our approach¶
In Xarray-Beam, distributed Xarray datasets are represented by Beam PCollections
of (xarray_beam.Key, xarray.Dataset) pairs, corresponding to a “chunk” of a
larger (virtual) dataset. The Key provides sufficient
metadata for Beam PTransforms like those included in Xarray-Beam to perform
collective operations on the entire dataset. This chunking model is highly
flexible, allowing datasets to be split across multiple variables and/or
into orthogonal, contiguous “chunks” along dimensions.
Xarray-Beam does not (yet) include high-level abstrations like a “distributed dataset” object. Users need to have a mental model for how their data pipeline is distributed across many machines, which is facilitated by its direct representation as a Beam pipeline. (In our experience, building such a mental model is basically required to get good performance out of large-scale pipelines, anyways.)
Implementation wise, Xarray-Beam is a thin layer on top of existing libraries for working with large-scale Xarray datasets. For example, it leverages Dask for describing lazy arrays and for executing multi-threaded computation on a single machine.
How does Dask compare?¶
We love Dask! Xarray-Beam explores a different part of the design space for distributed data pipelines than Xarray’s built-in Dask integration:
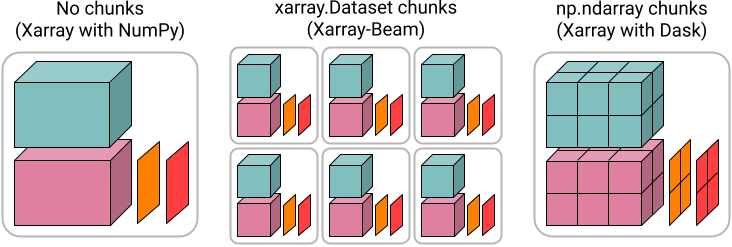
Xarray-Beam is built around explicit manipulation of
(xarray_beam.Key, xarray.Dataset). This requires more boilerplate but is also more robust than generating distributed computation graphs in Dask using Xarray’s built-in API.Xarray-Beam distributes datasets by splitting them into many
xarray.Datasetchunks, rather than the chunks of NumPy arrays typically used by Xarray with Dask (unless using xarray.map_blocks). Chunks of datasets is a more convenient data-model for writing ad-hoc whole dataset transformations, but is potentially a bit less efficient.Beam (like Spark) was designed around a higher-level model for distributed computation than Dask (although Dask has been making progress in this direction). Roughly speaking, this trade-off favors scalability over flexibility.
Beam allows for executing distributed computation using multiple runners, notably including Google Cloud Dataflow and Apache Spark. These runners are more mature than Dask, and in many cases are supported as a service by major commercial cloud providers.
These design choices are not set in stone. In particular, in the future we
could imagine writing a high-level xarray_beam.Dataset that emulates the
xarray.Dataset API, similar to the popular high-level DataFrame APIs in Beam,
Spark and Dask. This could be built on top of the lower-level transformations
currently in Xarray-Beam, or alternatively could use a “chunks of NumPy arrays”
representation similar to that used by dask.array.